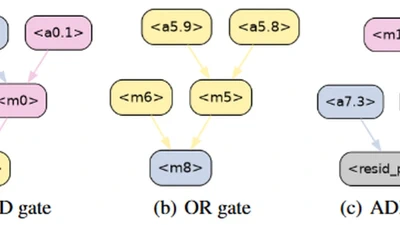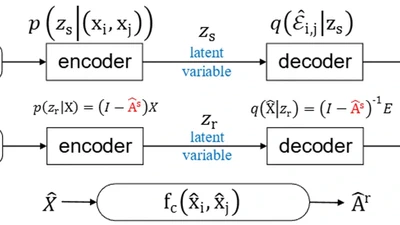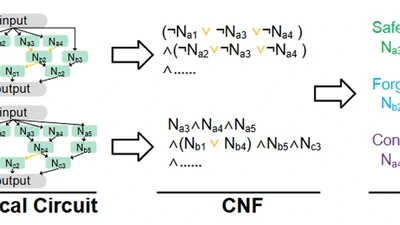
CLUE: Conflict-guided Localization for LLM Unlearning Framework
The LLM unlearning aims to eliminate the influence of undesirable data without affecting causally unrelated information. This process typically involves using a forget set to …
hang-chen-jiaying-zhu-xinyu-yang-wenya-wang